⚡ Quick Answer
A local LLM SQL data analyst is a self-hosted system that turns natural-language questions into SQL, checks the query, and executes it against approved data sources. It works best when teams combine a local model with schema grounding, query validation, execution guards, and a human review path for risky actions.
Local LLM SQL data analyst projects are taking off because they fix a very ordinary, very stubborn problem: analysts and operators don't want to hand-write the same SQL again and again. Simple enough. The pitch sounds easy. Ask a model a question, let it draft the query, check the result, then run it against the warehouse. But convenience isn't the whole story. Local models give teams tighter privacy, lower marginal cost, and far more say over how the system behaves day to day. That's a bigger shift than it sounds. So this pattern matters well beyond hobby demos.
What is a local LLM SQL data analyst and why are teams building one

A local LLM SQL data analyst turns plain-language questions into SQL, checks the output, and executes only approved queries on local or tightly controlled infrastructure. That's the core idea. Teams are building these systems because sending internal schemas, customer records, or finance data to outside APIs creates governance trouble fast, especially in healthcare, banking, and enterprise IT. Privacy pulls people in first. Cost and control follow right behind. And tools like Ollama, LM Studio, vLLM, plus models from Mistral and Llama, have made self-hosted inference much easier than it was even two years ago. That has changed the economics in a real way. We'd argue this shift doesn't get enough attention. A company can now pair a local model with PostgreSQL, DuckDB, or ClickHouse and build a useful SQL assistant without shipping sensitive metadata to a third party. Take Stripe-style finance reporting as a concrete example. This supporting article should also point readers back to pillar topic ID 388 and sibling pieces on AI agents, orchestration, and production safeguards.
How to build AI powered data analyst with SQL that actually works
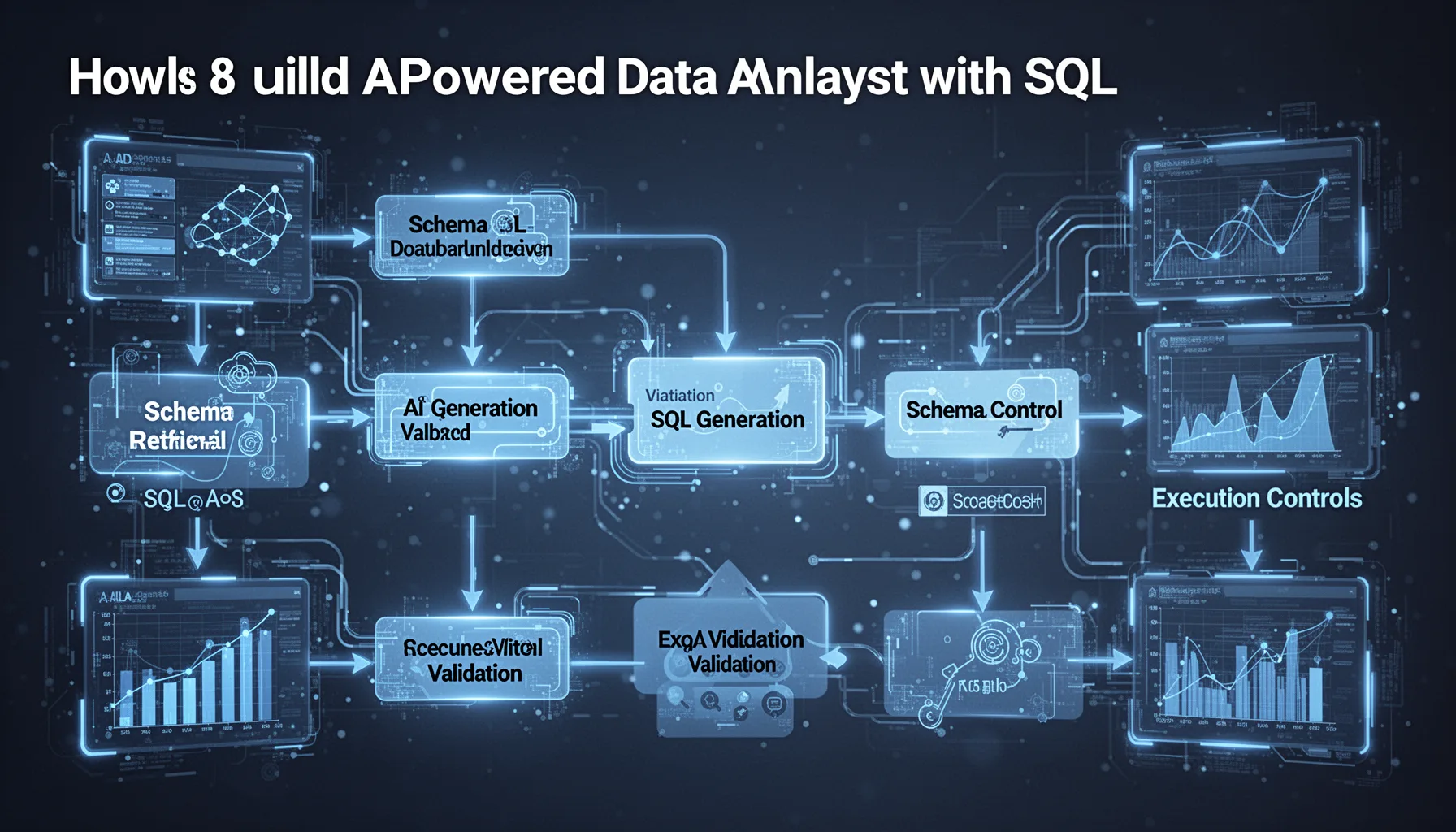
To build AI powered data analyst with SQL that actually works, you need a pipeline for schema retrieval, SQL generation, validation, execution controls, and result formatting. Not just a prompt. The usual mistake comes when teams treat SQL generation as the whole product, even though the real system also depends on prompt design, database permissions, query linting, and fallback behavior. That's where projects usually break. A sound architecture often starts with embedded table and column metadata for retrieval, then passes the relevant schema into the model before asking for a query. Systems like LangChain, LlamaIndex, and DSPy can orchestrate those stages, though we'd argue a smaller custom pipeline often stays easier to debug. Worth noting. Consider one concrete stack: a local Mistral model through Ollama, sqlglot for validation, PostgreSQL read replicas for execution, and a review screen before expensive joins or any write operation. That setup isn't flashy. But it's much closer to a production-grade local LLM for SQL query generation than the average notebook demo. Here's the thing.
Why validation matters in an AI system that writes validates and executes SQL

Validation matters because an AI system that writes, validates, and executes SQL can fail quietly in ways that still look believable to non-experts. SQL is deceptive. A query can be syntactically valid and still hit the wrong table, pick the wrong time grain, double-count rows after a join, or expose columns a user shouldn't see. So validation needs several layers: syntax checks, schema checks, semantic rules, permission enforcement, and sometimes a second model or rule engine that critiques the query before execution. Snowflake, Databricks, and dbt have all pushed teams toward stronger data contracts and firmer governance habits, and the same rules apply here. We'd say that's the real dividing line between a toy and a trustworthy assistant. Think of a dbt metric gone wrong. If your self hosted AI data analyst can't explain why it chose a join, estimate cost, and refuse risky queries, you haven't built an analyst. You've built a gamble. Not quite.
Which use cases fit a self hosted AI data analyst best
A self hosted AI data analyst works best in internal analytics, operational reporting, and domain-specific exploration where schema scope stays clear and permissions are well defined. That's the sweet spot. Early deployments often do well for sales dashboards, support reporting, cloud cost analysis, and product telemetry because the questions repeat and the tables don't change every hour. But broad ambition usually backfires early. One practical example is an ops team using a local model with DuckDB and Parquet logs to answer incident questions without waiting on a data engineer during an outage. That can save real time. We think narrow domain focus beats sprawling enterprise scope here. Teams should avoid starting with open-ended company-wide analytics across dozens of messy sources because query correctness and access control get complicated fast. Worth noting. This supporting piece also complements pillar topic ID 388 and sibling topics on agent reliability, evaluation, and self-hosted production AI systems.
Step-by-Step Guide
- 1
Choose a local model stack
Pick a local model that fits your hardware and SQL complexity needs. Many teams start with Mistral, Llama, or Code Llama variants through Ollama, vLLM, or LM Studio. Test latency early. A model that feels sluggish won't get used.
- 2
Ground the model in database schema
Pass current table names, column descriptions, foreign key hints, and sample values into the prompt or retrieval layer. This sharply improves accuracy compared with generic prompting. Keep the schema fresh. Stale metadata produces bad SQL with false confidence.
- 3
Add a validation layer
Validate syntax, schema references, query cost, and permission rules before execution. Tools like sqlglot can parse SQL, while custom guardrails can block writes, cross-database joins, or full-table scans. This step matters most. It's where production reliability begins.
- 4
Restrict execution permissions
Run queries against read-only roles, read replicas, or sandboxed engines whenever possible. Separate the generation service from database credentials and log every executed statement. That's basic hygiene. And it limits damage when the model gets creative.
- 5
Design a human review path
Ask for confirmation on expensive, ambiguous, or policy-sensitive queries. Show the generated SQL, the tables touched, and a plain-language explanation before execution. Humans don't need to approve everything. But they should approve the stuff that can hurt you.
- 6
Measure query quality in production
Track execution success, semantic accuracy, latency, retry rates, and user satisfaction after deployment. Build a test suite of known business questions and expected SQL patterns. Then keep scoring the system over time. Local LLM SQL data analyst quality lives or dies by evaluation.
Key Statistics
Frequently Asked Questions
Key Takeaways
- ✓A local LLM SQL data analyst gives teams privacy, control, and lower ongoing inference costs.
- ✓Schema grounding matters more than model size for reliable SQL query generation.
- ✓Validation and execution guards separate demos from production AI data systems.
- ✓Self hosted AI data analyst setups fit internal analytics and regulated data especially well.
- ✓This topic supports pillar 388 and connects to sibling articles on production AI agents.